Navigating the Data Symphony - A Deep Dive into Apache Hive’s Orchestration
Harmonizing Big Data - Unraveling the Symphony of Apache Hive’s Orchestration
Navigating the Data Symphony: A Deep Dive into Apache Hive’s Orchestration
In Big Data, Apache Hive emerges as a conductor, orchestrating a symphony of components to transform raw data into actionable insights. This article explains the intricate architecture of Hive, where the virtuosos - Hive Driver, Compiler, Optimizer, Thrift Server, and Clients - harmonize to give seamless big data processing.
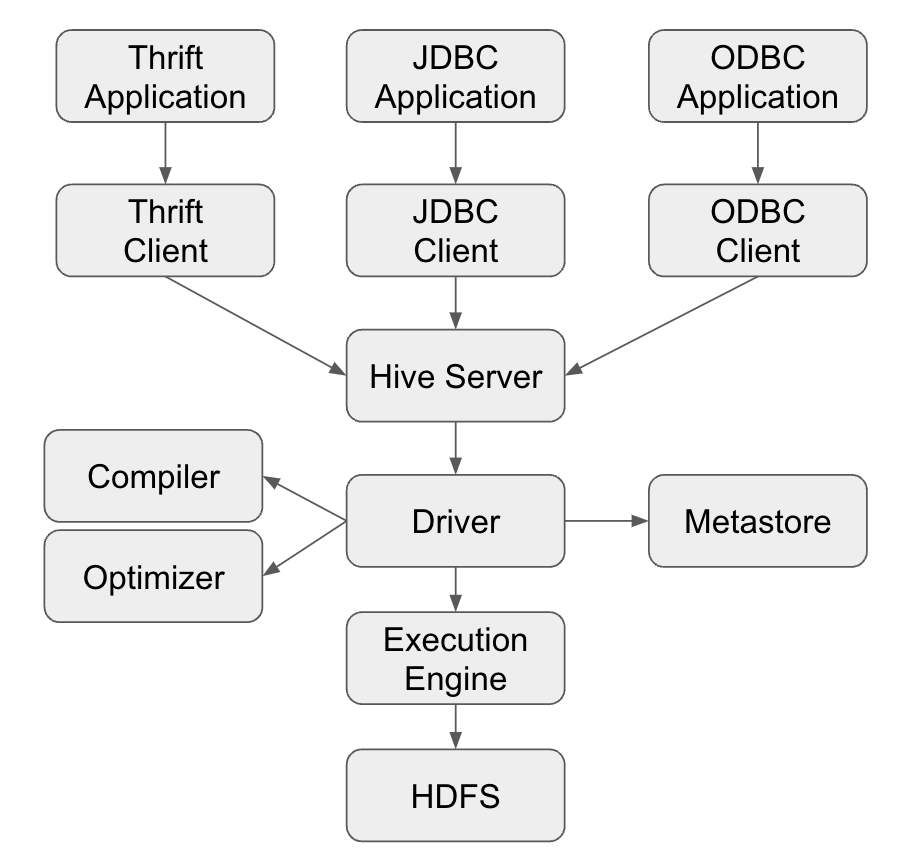
Hive Architecture
The Collaborators: Hive Clients

Photo by Clay Banks on Unsplash
The symphony of processing begins with a diverse ensemble of Hive Clients. These versatile messengers are fluent in various programming languages and bring user queries to the Thrift server. The three distinct messengers are the Thift Clients, JDBC Clients, and ODBC Clients - each adding its own note to the harmonious interaction between users and Apache Hive
The Maestro: Hive Thrift Server

Photo by Kristina Paparo on Unsplash
At the center of the ensemble is the Hive Thrift Server, which facilitates communication between the client and Hive services. Imagine it to be the maestro guiding different instruments to play in unison.
- The Thrift server is built on top of Apache thrift protocol, which overcomes language barriers. It supports clients in Java, Python, C++, Ruby, and more, to communicate seamlessly with Hive.
- It supports concurrent requests supporting multiple clients more like the symphony playing without an interruption.
- With the advent of Hive Server 2, it supports open API clients like JDBC and ODBC.
The Maestro’s Baton: Hive Driver

Photo by Alex Cooper on Unsplash
- Query Compilation and Session Handling: The Hive driver initiates the compilation process transforming user queries into a series of executable tasks. It also manages sessions isolating each query.
- Execution Initiation and Task Coordination: The driver takes charge once the execution plan is ready and initiates executions and coordinates the tasks on the Hadoop Cluster. It acts as the orchestra conductor, ensuring a synchronized performance.
The Composer: Hive Compiler

Photo by James Owen on Unsplash
- Query Parsing and Semantic Analysis: The compiler parses HiveQL queries with correct syntax and performs semantic analysis by validating against Hive Metastore rules.
- Execution Plan Generation and Optimization Strategies: Crafts an execution plan as a Directed Acyclic Graph (DAG) and identifies basic optimization opportunities while leaving the complex optimization to the next performer - The Optimizer
The Repository: Metastore
- The MetaData Storage: The Metastore acts as the repository of knowledge. It stores metadata about table structures, partitions, columns, serializers, and deserializers. Implemented as a Relational Database, it provides a Thrift interface for querying and manipulating Hive metadata
- Configuration Modes: In the remote mode, it operates as a Thrift service, ideal for non-Java applications, and in the embedded mode it allows direct interaction with the Metastore using JDBC, ideal for Java applications
The Virtuoso: Optimizer
- Optimization Strategies: The optimizer refines the execution plan with strategies like predicate pushdown, cost-based optimization, and task parallelization for improved efficiency
- Integration with Execution Engine: The optimizer submits the plan to the execution engine which further translates the logical plan into actionable tasks on the Hadoop cluster.
The Powerhouse: Execution Engine

Photo by Chad Kirchoff on Unsplash
- Seamless Integration and Task Execution: The execution engine seamlessly integrates with Hadoop, leveraging its distributed processing capabilities and it adapts to various execution frameworks like MapReduce and Tez, ensuring optimal performance for diverse queries. The engine translates logical execution plans into tasks and ensures orderly execution for data integrity and coherence.
- Optimization and Efficiency: The execution engine executes the optimized execution plan crafted by the optimizer. The execution engine evaluates the expense of different operations within the plan and selects the most cost-effective path saving the resources. The execution engine utilizes a deserializer associated with tables and reads the rows directly from HDFS Files. Once the output is generated, it is stored in temporary HDFS Files through serilizers which serve as intermediates in the next stage-finally giving back the results to the client as required.
Users cast queries like musical notes and Apache Hive, conducted by the dance of components - the Thrift Server, Driver, Compiler, Optimizer, Metastore, and Execution engine, bringing their data aspirations to life in the dynamic landscape of big data.